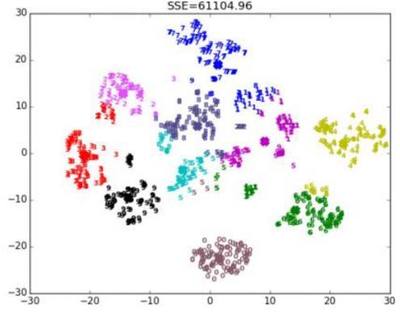
Kmeans聚类算法简介由于其出色的速度和良好的可扩展性,Kmeans聚类算法是最著名的聚类方法。谱聚类算法总结了三种聚类方法:均值聚类、密度聚类、层次聚类和谱聚类,谱聚类是一种基于图论的聚类方法,它将一个加权无向图分成两个或多个最优子图,使子图尽可能相似,子图之间的距离尽可能远,从而达到共同聚类的目的。
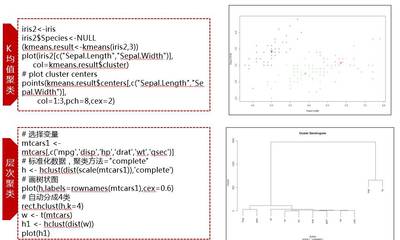
1、八:聚类算法K-means(20191223-29
学习内容:无监督聚类算法KMeanskmeans:模型原理、收敛过程、超参数选择聚类分析是在数据中寻找数据对象之间的关系,对数据进行分组。组内相似度越大,组间差异越大,聚类效果越好。不同的聚类类型:聚类旨在发现有用的对象聚类。现实中我们使用的聚类类型很多,用不同的聚类类型划分数据的结果是不一样的。基于原型(Prototype-based):一个集群是一个对象的集合,其中每个对象与定义该集群的原型之间的距离比其他集群之间的距离更近。如(b)所示,原型是中心点,一个聚类中的数据离它的中心点比离另一个聚类的中心点近。
这种簇趋向于球形。基于密度:聚类是对象的密度区域,(d)显示基于密度的聚类。当聚类是不规则的或交织的,并且存在早晨和异常值时,通常使用基于密度的聚类定义。有关群集的更多介绍,请参考数据挖掘简介。基本聚类分析算法1。K-means:基于原型,分割距离技术,它试图找到一个用户指定数量(k)的聚类。
2、三种聚类方法:层次、K均值、密度
1。层次聚类1)距离和相似系数r Dist (x,方法欧几里得,diagfalse,upper false,p2)用于计算距离。其中x是样本矩阵或数据帧。方法指示要计算的距离。method的值有:欧氏距离,即平方和平方。最大切比雪夫距离曼哈顿绝对距离堪培拉距离闵可夫斯基距离闵可夫斯基距离,当使用它时,指定P值二进制的定性变量距离。定性变量距离:注意m项中0:0对的个数为m0。
当upper为真时,给出上三角矩阵的值。R语言中使用Scale(x,centerTRUE,scaleTRUE)来集中和标准化数据矩阵。例如,如果只有Scale (x,scalef)是集中的,则sweep(x,MARGIN,STATS,FUN,…)用于计算R语言中的矩阵。
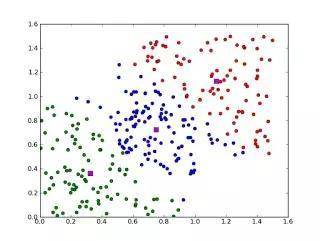
3、四种聚类方法之比较
四种聚类方法的比较本文介绍了kmeans、层次聚类、SOM和FCM等四种常见的聚类算法,阐述了各自的原理和应用步骤,并使用国际通用测试数据集IRIS对这些算法进行了验证和比较。结果表明,FCM和kmeans的准确率较高,层次聚类的准确率最差,SOM耗时最长。关键词:聚类算法;kmeans层次聚类;SOMFCM聚类分析是一种重要的人类行为。早在童年时期,一个人就通过不断改进潜意识聚类模型,学会了如何区分猫、狗、动物和植物。
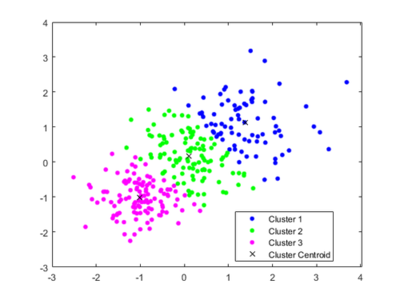
4、Kmeans聚类算法简介
Kmeans聚类算法由于其卓越的速度和良好的可扩展性而成为最著名的聚类方法。Kmeans算法是一个反复移动类中心点的过程。它将类的中心点(也称为重心)移动到其成员的平均位置,然后重新划分其内部成员。k是算法计算的超参数,表示类别数;Kmeans可以自动将样本分配到不同的类,但不能决定划分多少个类。
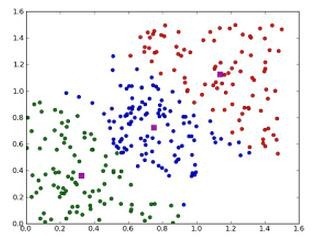
有时候,课时数是由问题内容指定的。例如,一家鞋厂有三种新款式,它想知道每种新款式的潜在客户是谁,所以它对客户进行了调查,并从数据中找出了三个类别。还有一些问题没有指定聚类数,最优聚类数是不确定的。后面我会详细介绍一些估算最优聚类数的方法。Kmeans的参数是类的重心位置及其内部观测的位置。与广义线性模型和决策树类似,Kmeans参数的最优解也是以最小化代价函数为目标。
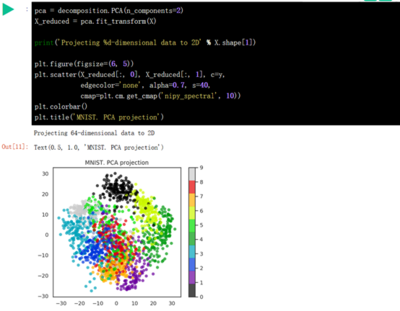
5、K-Means聚类算法
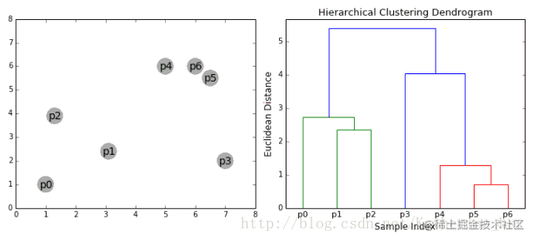
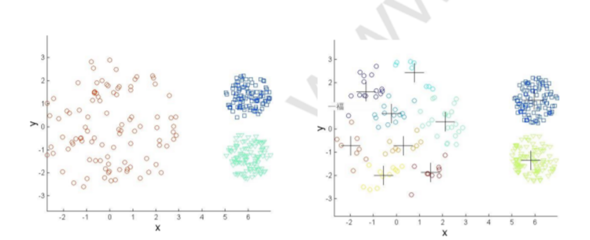
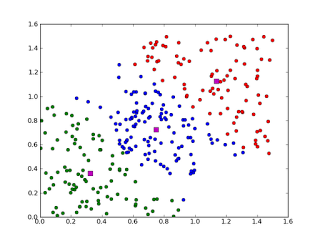
所谓聚类算法,是指将一堆未标记的数据自动分成若干类的方法,属于无监督学习方法。这种方法要保证同一类别的数据具有相似的特征,如下图所示:根据样本之间的距离或相似度(亲和力),将相似度较大、差异较小的样本归为一类(聚类),最后形成多个聚类,使同一聚类内的样本具有较高的相似度。相关概念:k值:要获得的聚类数;质心:每个聚类的均值向量,即可以通过平均向量的维数来度量距离;欧氏距离和余弦相似度(第一次标准化)算法流程:1。首先确定一个k值,也就是我们希望对数据集进行聚类得到k个集合。
3.对于数据集中的每个点,计算其与每个质心的距离(如欧几里德距离)。如果它靠近哪个质心,它将被划分到该质心所属的集合中。4.把所有数据放在一起,就有K个集合。然后重新计算每组的质心。5.如果新计算的质心与原质心的距离小于设定的阈值(表明重新计算的质心位置变化很小,趋于稳定,或者收敛),我们可以认为聚类达到了预期的结果,算法终止。
6、大数据分析之聚类算法
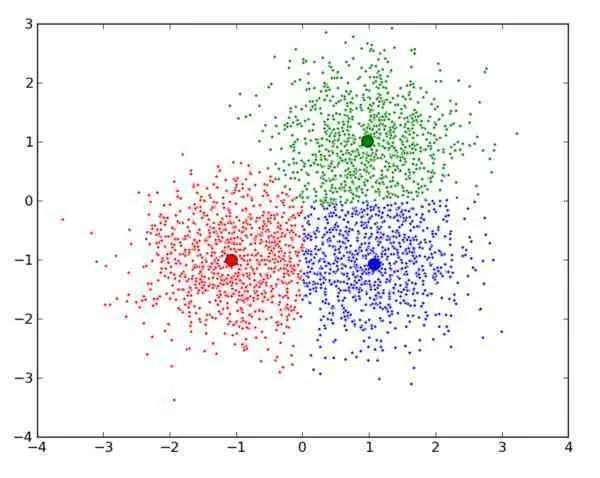
大数据分析的聚类算法1。什么是聚类算法?所谓聚类,就是比如给定一些元素或对象,将它们分散存储在数据库中,然后按照我们感兴趣的对象的属性进行聚合。相似对象之间相似度高,不同类之间差异大。最大的特点就是没有提前确定品类。最经典的算法是KMeans算法,最常用的聚类算法。主要思想是:给定k值和k个初始聚类中心点,将每个点(即数据记录)划分到最近的聚类中心点所代表的聚类中,所有的点都分配后,根据一个聚类中的所有点重新计算聚类中心点(平均值)。
7、什么是聚类分析?聚类算法有哪几种
聚类分析又称聚类分析,是一种研究(样本或指标)分类的统计分析方法。聚类分析起源于分类学。在古代分类学中,人们主要依靠经验和专业知识来实现分类,很少使用数学工具进行定量分类。随着人类科技的发展,对分类的要求越来越高,以至于仅凭经验和专业知识有时难以准确分类,于是人们逐渐将数学工具引入分类学,形成数值分类学,再将多元分析技术引入数值分类学,形成聚类分析。
聚类分析的计算方法主要有以下几种:划分法、层次法、基于密度的方法、基于网格的方法和基于模型的方法。
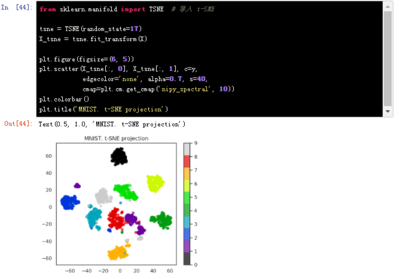
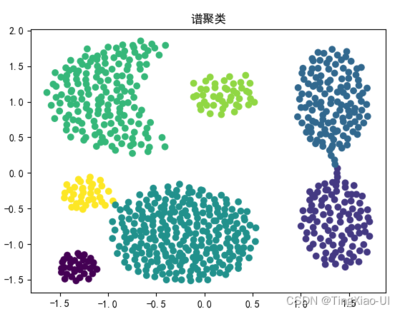
8、谱聚类算法总结
聚类三种方法:kmeans聚类、密度聚类、层次聚类和谱聚类谱聚类是一种基于图论的聚类方法,将一个加权无向图分成两个或两个以上的最优子图,使子图尽可能相似,子图之间的距离尽可能远,从而达到共同聚类的目的。其中最优性是指最优目标函数不同,可以是最小割,也可以是规模和最小割相近的划分。
并计算矩阵的特征值和特征向量,然后选择合适的特征向量对不同的数据点进行聚类。谱聚类算法最初用于计算机视觉、VLSI设计等领域,最近开始用于机器学习,并迅速成为国际上机器学习领域的研究热点。谱聚类算法基于谱图论,其本质是将聚类问题转化为图的最优划分问题。这是一种点对点的聚类算法。与传统的聚类算法相比,它具有在任意样本空间上聚类和收敛到全局最优解的优点。
9、分类和聚类的区别及各自的常见算法
1、分类和聚类的区别:分类,对于一个分类器来说,你通常需要告诉它一些例子比如“这个东西分一定的类”。理想情况下,分类器将从它获得的训练集中“学习”,从而有能力对未知数据进行分类。这种提供训练数据的过程通常被称为监督学习和聚类。简单来说就是把相似的东西归为一组。聚类的时候,我们不在乎某个类是什么。我们需要实现的只是把相似的东西凑在一起。
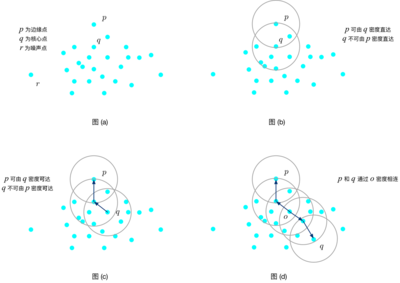
10、有哪些 常用的聚类算法
聚类方法分为以下几类:分割方法:kmeans分层方法:rock,chemeleon基于密度的方法:dbscan基于网格的方法:sting,wavecluster等。【聚类】聚类分析直接比较对象的属性,根据对象属性中描述对象及其关系的信息对数据对象进行分组。目标是组中的对象彼此相似(相关),而不同组中的对象不同(不相关)。
聚类的目标是通过学习未标记的训练样本来揭示数据的内在属性和规律,这是一个无监督的学习过程。在无监督学习中,训练样本的标记信息是未知的,聚类试图将数据集中的样本分成几个不相交的子集,每个子集称为一个“簇”,每个簇可能对应一些潜在的类别。这些类别概念对于聚类算法来说是事先未知的,聚类过程只能自动形成一个簇结构,簇对应的概念语义需要用户去掌握和命名。